2018-08-07
Simpler Topic Modelling#
During my last bout with insomnia I decided I wanted to get a bit more familiar with python's regex, pandas and PRAW Reddit API all at the same time. This turned into an exploratory saga into topic modelling, a fascinating subset of natural language processing that uncovers common topics within text data. As a random mini-task, I'd decided to try mining new r/news posts to find current popular topics, then return matching articles.
Typically, it's as complicated as it is useful. Categorizing organic text requires contextual pattern recognition that's easy for humans, but not rule-based enough to easily program. It's most successfully done through unsupervised machine learning, generally going something like this:
- Clean data: Remove stopwords and transform into a Document x Word matrix where each document is represented by an array of word-frequency.
- Find topics: Group together words that often show up in the same documents. Produce Word x Topic matrix.
- Analyze documents: Evaluate how much each document belongs to each topic. Produce Topic x Document matrix.
Notably, the 'topics' of topic modelling are not descriptors as you and I would expect (eg: war) but instead represented by groupings of words commonly used together (eg: guns, soldiers, MIA, General).
The most popular method is Latent Dirichlet allocation, a generative probabilistic extension of pLSA. Python: Real-World Data Science has a full chapter on a very similar project using a k-means clustering algorithm. There's of course out-of-the-box libraries like nltk, but I didn't want to use it without properly understanding it.
The most obvious way, clearly, is to go to r/news and sort by hot or top, but that wouldn't be complicated enough. It also often spams you with ten articles about the story of the day, and only a couple of anything else. One of my goals is to return just one article per topic.
I felt these were all far too complicated for my simple purposes. My attempts to hack my way into a simpler, but still working, approximation grew more involved than expected. After initial failure, I tried to apply some classical theory to my work, while staying mathematically straightforward. In the end, I did manage to make the classification better - though note that 'better' is a relative term.
Common Proper Nouns#
So, having spurned classical topic modelling in favour of hacking my way through, I decided I'd manage well enough by equating the most popular topic to the most common proper nouns. It seemed sensible. Proper nouns = topics, most common = most popular. No?
👁️🗨️ Tip
Proper Noun: A proper noun is the name of a particular person, place, organization, or thing. Proper nouns begin with a capital letter.
# regex proper nouns
ProperNouns = re.findall(r'[A-Z][a-z]+', all_titles)
# get 12 most common
search_terms = pd.Series(ProperNouns).value_counts().nlargest(12)No. This turned out worse than I hoped. My regex search pattern matches proper nouns, yes, but also the first word in a sentence and anything from capslock-happy posters. My initial list looked something like this:
Counts:
The 37
News 19
New 19
Man 18
Woman 17
Judge 16
Florida 15
California 15
Is 15
Police 14Stop, it's a word.#
Many of these, like 'the' and 'is', are stop words - words excluded from search queries and language processing because they're irrelevant or too common. These should be removed when cleaning text prior to processing, to isolate only pertinent data. There's no one conclusive list, since relevance can vary depending on use case. I amassed my own ad-hoc, with some indecision. Sigh. Anyway, I felt I'd solved the issue and could now reasonably pick the top hits as search terms:
Counts:
Police 18
California 17
Korea 15
Florida 15
Fire 15
County 14
Zimbabwe 14
Former 14
Mexican 13Looking at these, I fully expected I'd successfully isolated the main topics, probably with some overlap. I planned on regex-ing for titles associated with each term, picking the one with most votes, then returning all unique results. Surely this would give me a good summary of the biggest topics! I predicted output like; "Police shootout in California leaves 2 dead," "Florida Fire claims a new County," and "Former Mexican president killed in Zimbabwe; imperils Korea peace talks."
Such high hopes.
Yes, that is foreshadowing..
Now I finally had complete, simple code:
import praw
import re
import pandas as pd
# connect to reddit with praw
reddit = praw.Reddit(client_id='my_id', client_secret='my_secret', user_agent='me')
# get new submissions from News
submissions = []
for submission in reddit.subreddit("News").new(limit = None):
submissions.append([submission.title, submission.score])
submissions = pd.DataFrame(submissions, columns = ['titles', 'scores'])
# get most common proper nouns
stop_words = 'In|The|Man|New|What|My|This|Woman|Best|Why|How|You|Is|Part|To|After|First|No|Boy'
all_titles = re.sub(stop_words, "", " ". join(submissions.titles))
ProperNouns = re.findall(r'[A-Z][a-z]+', all_titles)
search_terms = pd.Series(ProperNouns).value_counts().nlargest(10).index.values
# return all submissions referencing one of the search terms with more than 200 upvotes
for term in search_terms:
print "\n\n Titles about " + term + ":"
print submissions[(submissions.titles.str.contains("(?i)"+term)) & (submissions['scores'] >= 100)]It outputted as it should. Everything was wonderful.
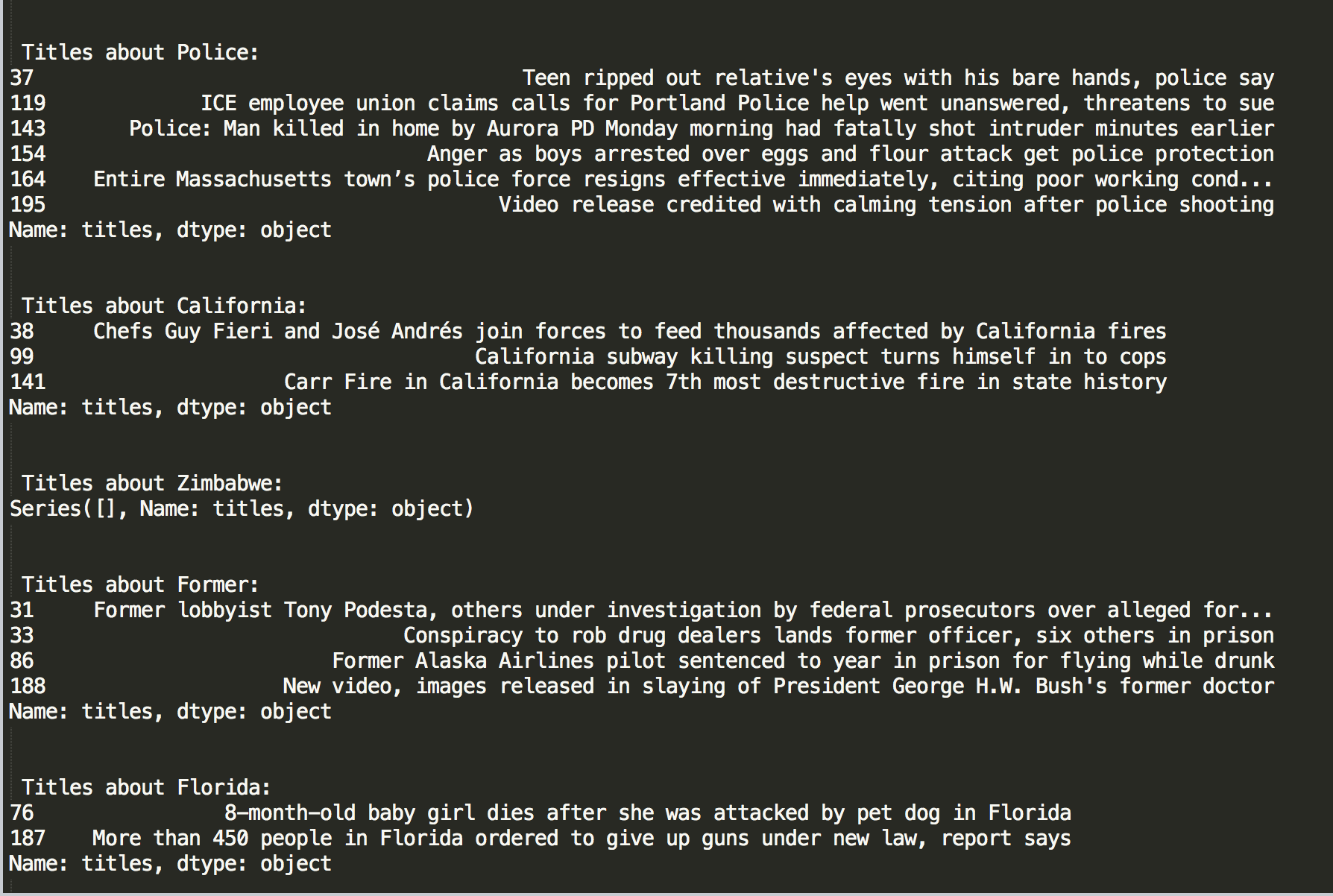
Yes, the code worked perfectly. But you remember that earlier foreshadowing? It comes in here. Conceptually, my plan failed.
Such issues much wow#
Natural language processing is decently complicated. It may have been a touch presumptuous of me to think I'd solved it. Especially since I intentionally skipped over the many functionality-specific topic modelling tutorials and examples available to me.
First, and retrospectively obvious, 'common' does not immediately translate to 'popular'. None of the submissions about Zimbabwe even made the >100 upvotes cut, so clearly nobody cared about that. This is easily resolved by weighting each proper noun by the amount of votes the submission got.
More problematically, the most commonly used proper nouns didn't cluster the articles like I wanted. In all the submissions, only two events showed up more than once - a shooting and the California Carr fire. Out of ~30 results, that's a terrible hit rate.
It didn't work - except it did. The articles were clustered by topic, but those topics were a lot broader than desired. Florida articles were grouped together, California articles, etc. I want to be a lot more specific; I want to group stories, not topics.
Pick-pocketing from Topic Modelling#
See, topic modelling generally assumes that the entire body of text inputs are represented by a few topics. It also assumes that each document covers multiple topics, to varying degrees. This results in a very interlinked web of topics and documents, as seen below. While it's possible to increase the number of topics the model looks for, this generally just ends up giving you nonsense.
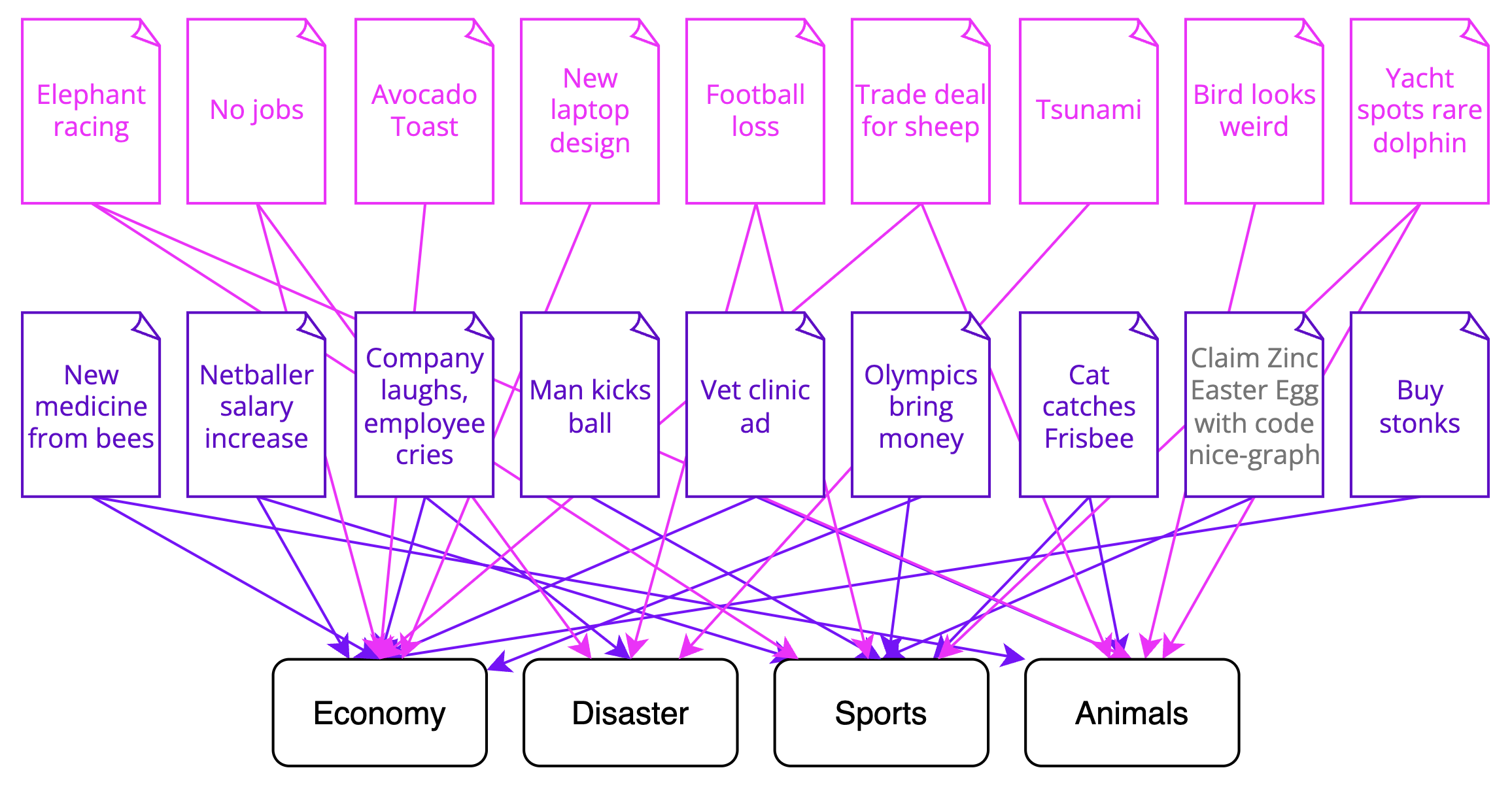
This looks like it'll run into the same issues as my common proper nouns method; the topic groups it finds are going to be way to general. In my context, each article represents a single event, and the majority of events will only be represented once. Topic modelling, for all the flair, is probably not the most effective method for doing this.
In the meantime, I still like my personalized news feed. It's adorable, in a lopsided half-bred mutt kinda way. And I can improve on it - possibly still learn a little from the classic topic model. To recap, each generally works by:
- Cleaning: remove text to retain only relevant words
- Analysis: group words that often appear together as 'topics'
- Sorting: assign texts to related topics
My 'proper nouns' solution is honestly more cleaning than analysis. I'm considering only proper nouns to be relevant text data. Then I just take the most common single-items from this cleaned data, instead of the most common groups. Of course these topics have low definition. While most topic data algorithms are still too general for me, searching for common groups of words would make the search a lot more specific. The search 'California Fire' would have given me a lot closer to what I wanted than the separate searches for 'California' and 'Fire' did.
Multi-Word Groups:#
I started by explicitly cleaning the data when I fetched it, returning the set of all relevant words in each title. I switched to r/worldnews for a bigger dataset and adjusted the sort in my call to the reddit API to 'hot' instead of 'new', which should also help a bit with the common != popular issue:
submissions = []
titles = []
for submission in reddit.subreddit("worldnews").hot(limit = None):
titles.append(submission.title)
cleaned_title = re.sub(" | ".join(stop_words), " ", submission.title)
submissions.append(set(re.findall(r' [A-Z][a-z]+ ', cleaned_title)))Then came the issue of finding frequent word groups. One way to do this would be to find phrases, eg: 'California carr fire' or 'give up guns'. However, stories about the same event rarely use identical phrasing - there's a 'fire in California' as well as a 'California fire'. It seemed better to compare the combination, not permutation, of words in each title.
By now I was getting a little impatient and just brute-forced to find instances where multiple non-stopwords were shared between titles. It's not particularly efficient, but it gets the job done:
submissions = pd.DataFrame({'title' : titles, 'cleaned' : word_groups})
topics = []
for sub in submissions.itertuples():
for sub2 in submissions.itertuples():
shared_words = sub.cleaned.intersection(sub2.cleaned)
if len(shared_words) > 2
topics.append(shared_words)Printing out the sets showed that I was clearly getting a lot more sensible word groupings:
> [u'Arabia', u'Saudi', u'Canadian']
> [u'Korea', u'North', u'Trump']
> [u'Korea', u'North', u'Trump']
> [u'China', u'Korea', u'North']
> [u'Osama', u'Hamza', u'Laden']
> [u'The', u'Druze', u'Israel']
> [u'Aviv', u'Jewish', u'Israel', u'Tel', u'Druze']
> [u'Jewish', u'Israel', u'Druze']
> [u'Aviv', u'Tel', u'Druze']
> [u'The', u'Israel', u'Druze']
> [u'Ai', u'Beijing', u'Weiwei', u'Chinese']
> [u'Ai', u'Authorities', u'Studio', u'Chinese']
> [u'Arabia', u'Saudi', u'Canadian']
> ...Duplicates and dirty data#
However, some problems clearly remained.
- My brute-force code gave me a bunch of duplicate entries. I added a clause in the for loop to not append if the titles were the exact same, and ditched any others by calling set() on the final list.
- There were many groups that were very similar, but not exactly the same.
- Cleaning the data for just proper nouns biased my results towards anything with somebody's name or a countries. It would probably be better to remove a more complete list of stopwords, then use all remaining words.
- The cleaning didn't seem to be properly successful; there were still a bunch of 'The' and 'In' that had successfully snuck there way in. This utterly perplexed me for a long while, until I came to the frustrating discovery that regex re.sub() only takes the first of overlapping matches. This is a problem since I was matching only if the stopwords had spaces on either side. This was somewhat necessary to prevent eg: 'Israel' from being turned into 'rael'. Simplest, if annoying, solution is just to call the same re.sub() command multiple times.
Solving the cleaning issues was decently straightforward. I finally broke out pythons natural learning toolkit library to borrow their list of english stopwords, which required way more steps than expected. Unfortunately a lot of nltk's datasets don't come automatically with the normal pip install and import. You need to download these separately:
you@console$ python
>>> import nltk
>>> nltk.download()This will open a new window, where you click download all. You also need to pick what language your dealing with in-script. Finally, better cleaning occured:
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
submissions = []
titles = []
for submission in reddit.subreddit("worldnews").hot(limit = None):
titles.append(submission.title)
cleaned_title = re.sub(" | ".join(stop_words), " ", submission.title.lower())
cleaned_title = re.sub(" | ".join(stop_words), " ", cleaned_title)
submissions.append(set(re.findall(r' [a-z]+ ', cleaned_title)))Now this? This is getting somewhere.
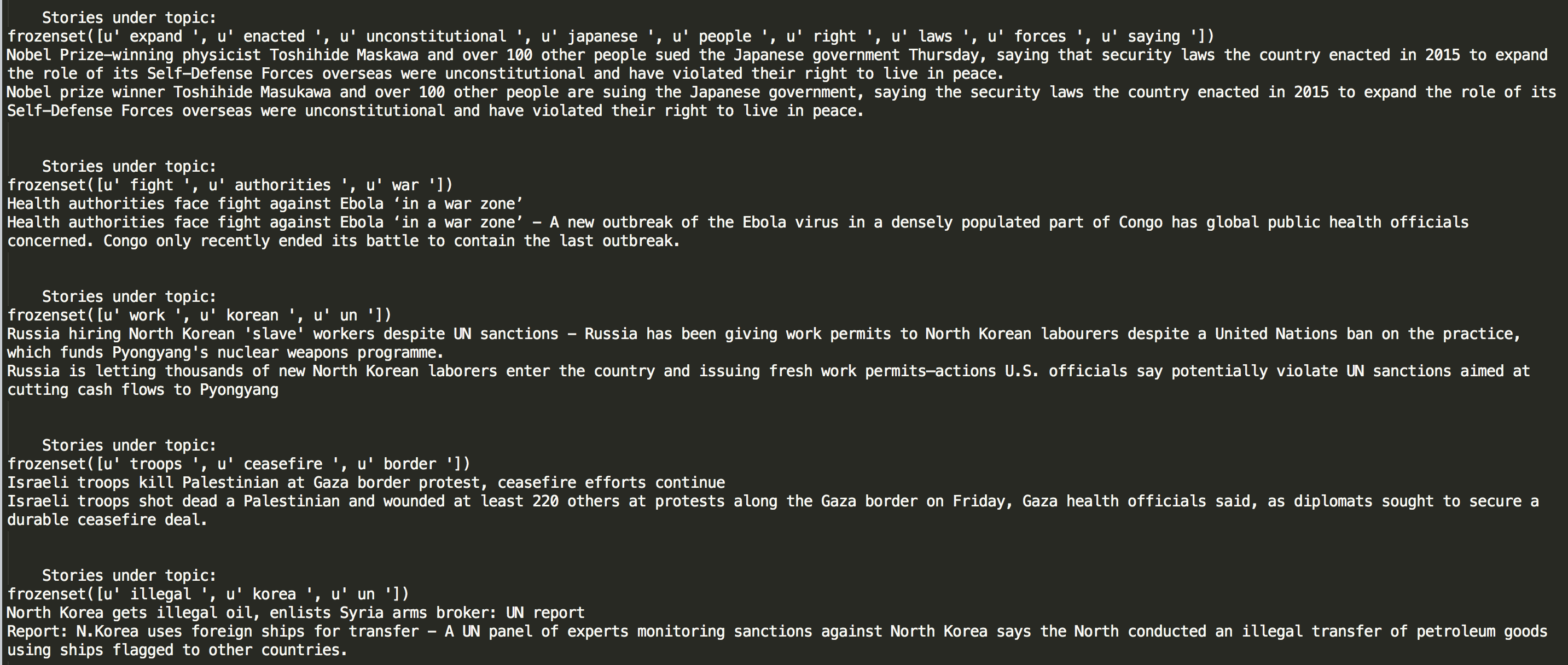
All of these groups feature (mostly) different articles about the same event. There's still some groups that refer to the same topic - three groups refer to N. Korean missile tests - but that's gotten better. I'm expecting them to disappear once I sort out the less popular ones. Of course, with my luck, it's more likely that we'll end up with only duplicates in the most popular ones.
Now it's time to shrink down the results. My resolution to return only one article per event was sorely tested by what has to be my favourite pairing ever:
> Stories under topic: (['japan', 'australia', 'whaling'])
> Australia Thursday vowed to vehemently oppose a new push by Japan to undermine a global moratorium on commercial whaling, and urged like-minded nations to stand firm against Tokyo.
> Japan and Australia agreed Friday to make efforts to prevent a dispute over whaling from hurting bilateral relations, a government official said.Suck backtrack, much wow.
Narrowing down the groups#
Anyway, on to finding the popular events. Equating this to commonly posted about didn't work out previously. I checked it out anyway, and unsurprisingly found that it was mostly events with duplicate or near-duplicate articles. Ah well.

Sorting by scores it is. At this point, I realized I'd stopped fetching the scores from reddit at some point. Whoops. Ah well, easy enough fix.
I started with 153 different topics. There's some variation to be expected, since the program fetches the most up-to-date 'hot' submissions from r/worldnews each time, but that should be minor. There's two obvious places where I could institute a score-check: when I'm creating the topic groups, and afterwards (most likely as part of the printing for loop). Doing it while creating the topic groups would be more efficient, since I wouldn't need to loop through the less popular ones later on. However, it would also give me less fine-grain control. I'm extracting topics from only two articles at a time, while there's possibly more that match. Doing it after would let me evaluate a topic given all relevant articles. I did it while creating the topic groups .
for sub in submissions.itertuples():
for sub2 in submissions.itertuples():
if sub.title != sub2.title and sub.score + sub2.score > 500:
shared_words = sub.cleaned.intersection(sub2.cleaned)
topics.append(frozenset(shared_words))if len(shared_words) > 2 else NoneIncluding topics only if the combined score of both articles was over 500 shrunk the number of topics down to 39. This was with significant overlap - Robert Meuller came up 8 times. It's probably time to try and tidy that up. This leaves me a bit puzzled, since it's basically the original problem all over again; I've got a couple of lists of words, and I want to isolate similar ones.
Topic modelling the goddamn topics.#
Seriously, I'm back to square one - except this time, with a bit of experience. I see two immediate possibilities:
- Find single words that show up in more than one topic
- Find groups of words that show up in more than one topic
For the original issue, the latter worked far better. Yet I suspect that the former might work best here - we've already shaved it down so far we shouldn't have any duplicates. Requiring more words would be both more lax and more complicated - the Meuller groups all have several things in common with something else, but nothing in common with everything else. Actually, this is also a problem with the single-word method, albeit less of one.
> ['robert', 'trump', 'donald', 'russia']
> [u'counsel', u'robert', u'russia']
> [u'donald', u'robert', u'trump', u'special']
> [u'mueller', u'white', u'trump']
> [u'robert', u'russia', u'special']
> [u'counsel', u'robert', u'special']I started with the single-word method, by finding all duplicate words in the set of topics and grouping accordingly. This yielded the same number of groups as I'd had topics. No, that wasn't an error, there were just a lot of duplicate code. I had better luck finding all groups that matched any part of one group:
grouped_topics = []
for topic in topics:
similar_topics = []
for topic2 in topics:
if len(topic.intersection(topic2)) > 0:
similar_topics.append(topic2)
if similar_topics not in grouped_topics and len(similar_topics) > 1:
grouped_topics.append(similar_topics)This gave me 15 groups. There were still duplicate groups; 4 for Trump/Mueller/Russia, 3 for Palestinian refugees, 3 for North Korean missiles. A couple of groups shouldn't have existed, and I realized I needed to add numbers to my stopwords. I also decided to exclude 'Trump', on the basis that 1) he turns up way too often, 2) it shouldn't effect finding topics for the worse, since other words (president, Donald, White House) are almost always used in conjunction, 3) he generally features in multiple events, so grouping based on him is a problem, and 4) I'm sick of him anyway.
I hadn't actually expected this to solve my grouping crisis, but it mostly did. My biggest problem was that there were three groups focused on N. Korean missiles. I finally said to hell with this and just merged any groups that had any items in common. I'm absolutely certain there's a more efficient way to do this:
grouped_grouped_topics = []
for group in grouped_topics:
for group2 in grouped_topics:
if len(group.intersection(group2)) > 0:
group = group.union(group2)
if group not in grouped_grouped_topics:
grouped_grouped_topics.append(group)This finally delivered my dream; it compressed 23 topics down into 7 sensible groups with no overlap. I was interested to find in the meantime that a Canadian ambassador had been expelled from Arabia. But it seems like I'm almost done.
Could this be... Success?#
With my topic grouping and >500 bound for the combined score, I ended up with 16 summary articles. All were independent, and decently important. They covered events from Tel Aviv to Bangladesh, including the classical White House scandals and technology updates as well as feel-good whale stories.

This is kinda awesome - it took a bunch of pivoting and head-scratching, but I've finally accomplished my goal! The top stories of the day, each covered by unique articles in a quick and accessible summary of relevant news. Can I confirm that these adequately represent the top of the news cycle?
Let's compare my results to the top-voted articles:
- The top-sorted articles were pretty repetitive, at around 2 titles/event. Mine was solidly 1 title/event, with excellent worldwide coverage.
- Of the 257 unique non-trivial words in the top 100 article titles, 164 were included in my top 16. That's a 65% hit rate, suggesting pretty good coverage.
- My articles were consistently longer than the top-sort ones. This makes much sense, since groups based on sharing multiple words statistically favour titles with more words. It's also gives more info in this title-only return format.
- Mine missed several pertinent items, like murdered journalists and heatwaves. This was likely because any event had to feature in multiple stories, with long titles, to create a topic.
Overall, pretty decent.
So What?#
It's a simple method to solve a tricky problem. As overburdened as the code is, this implementation translates the conceptual simplicity of topic modelling into practice. This is much more understandable than unsupervised machine learning. Shared word groups are found and grouped appropriately; this yields the desired level of topic detail. That point - the level of detail - does highlight that it's fairly application-specific, but still a success.
It works. It actually works; I accurately generated groups of articles that tightly represented specific events, with a pretty straightforward conceptual framework.
Conceptually, it could improve. Topic modelling might not be the right fit, but this isn't quite either. I could rephrase my initial goal; I want a single report for each of the top events. A more sensible take would be to get the top 30 articles, then find and remove duplicate events. This gets around the issue of needing multiple wordy titles for a topic, but could use generally the same methods.
Coding-wise, this sucks. Loops are oozing out at a glance and the list comprehensions border on incomprehensible. There's definitely better ways to do it - but there are times to properly research and craft simple, efficient programs that will run as fast as possible, then there are times to hack together something you can code as fast as possible. This is the latter.
I might always come back and improve the code sometime; at which point I will silently alter all my brute-force methods and remove every reference to them (including this one). Such revisionist history will allow future readers to believe in my genius in full ignorance of any previous mistakes.
Code#
The full code, by the end, had ballooned. Some of this was in cleaning, sure, but most went to the overcomplicated topic-grouping:
import praw
import re
import pandas as pd
from nltk.corpus import stopwords
# connect to reddit
reddit = praw.Reddit(client_id='D6v36GJPD07usA',
client_secret='y3opRvKVKhqj3X9gQwAaQdS4EXY',
user_agent='me')
# get cleaned submissions from News
stop_words = set(stopwords.words('english') + ['un', 'two', 'one', 'trump'])
word_groups = []
titles = []
scores = []
for submission in reddit.subreddit("worldnews").hot(limit = None):
titles.append(submission.title)
scores.append(submission.score)
cleaned_title = re.sub(" | ".join(stop_words), " ", submission.title.lower())
cleaned_title = re.sub(" | ".join(stop_words), " ", cleaned_title)
word_groups.append(set(re.findall(r'(?<= )[a-z]+(?= )', cleaned_title)))
print "Found %d submissions" % len(titles)
submissions = pd.DataFrame({'title' : titles, 'cleaned' : word_groups, 'score' : scores})
# get topics
topics = []
for sub in submissions.itertuples():
for sub2 in submissions.itertuples():
if sub.title != sub2.title and sub.score + sub2.score > 500:
shared_words = sub.cleaned.intersection(sub2.cleaned)
topics.append(frozenset(shared_words))if len(shared_words) > 2 else None
topics = set(topics)
# group similar topics
grouped_topics = []
for topic in topics:
similar_topics = []
for topic2 in topics:
if len(topic.intersection(topic2)) > 0:
similar_topics.append(topic2)
if similar_topics not in grouped_topics and len(similar_topics) > 0:
grouped_topics.append(set(similar_topics))
grouped_grouped_topics = []
for group in grouped_topics:
for group2 in grouped_topics:
if len(group.intersection(group2)) > 0:
group = group.union(group2)
if group not in grouped_grouped_topics:
grouped_grouped_topics.append(group)
used_topics = []
best_articles = []
# find most popular articles for all topics
for group in grouped_topics:
used_topics = used_topics + [topic for topic in group]
relevant_subs = submissions[[any([topic.issubset(sub.cleaned) for topic in group]) for sub in submissions.itertuples()]]
best_articles.append(relevant_subs.loc[relevant_subs.score.idxmax()])
for topic in topics:
if topic not in used_topics:
relevant_subs = submissions[topic.issubset(submissions.cleaned)]
best_articles.append(relevant_subs.loc[relevant_subs.score.idxmax()])
# print articles
for article in best_articles:
print "> " + article.title