2024-03-15
Ragging on RAG#
There's a hot new topic in AI. Frankly, there are many hot new topics in AI any day of the week, but we're going to focus on one right now: Retrieval Augmented Generation. This is meant to be a pretty straightforward article on what it is and why it exists. I found it hard to understand RAG at first through the jargonistic and technical details, so I'll do my best to make this approachable without assuming any knowledge.

Why should you care about RAG?#
RAG marries one of the oldest great technological masterpieces, Search, with one of the newest, Generative AI. So there's two different arguments for why RAG is great:
- Generative AI is amazing, but giving it access to more information makes it better.
- Search is amazing, but adding automatic summarization and analysis makes it better.
Let's start with the first one. It's the one that introduced me to RAG - and it's also the one that makes it easier to explain.

For this we'll turn around and go through the concepts of RAG backwards:
- Generation: What specifically am I talking about when I say GenAI?
- Augemented: Why does GenAI need to be augmented? How do you augment it?
- Retrieval: What is Retrieval? How does it come into GenAI?
Generation is pretty cool#
Enough people have [spoken] [for] [Generative] [AI] that I'm not going to rewrite the wheel here, and will assume you're all at least a little convinced that generation is pretty cool.
Instead let's get a high level understanding of how LLMs work, as pertains to this discussion. I'm abstracting away a lot of detail, so if you're comfortable with your existing knowledge, just skim through the pictures.
What are LLMs? An Oversimplification.#
Let's talk about [Large Language Models]. LLMs are a specific subset of GenAI that generate text. They took the world by storm in 2023 because they generate good text. This is a small but important distinction against previous types of AI.
To get an LLM, you first take the internet.

Then you take your LLM architecture and [pre-train] it: you run the internet through a lot of math, and end up with a working LLM - a computer program that holds in itself a deep understanding of the information and language structure of its input data (the internet).
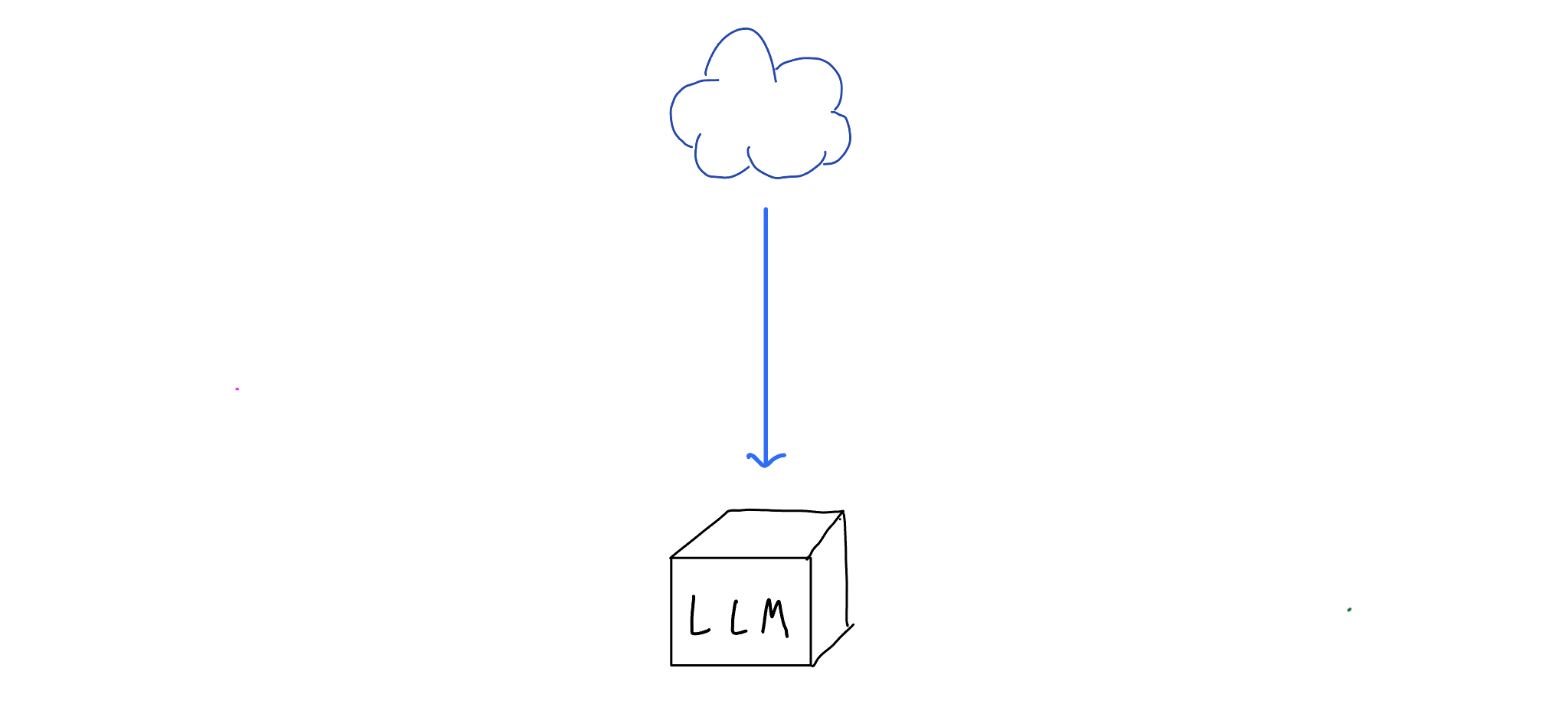
Now you have a LLM.
To use a LLM, you provide some input text - the prompt. The LLM then keeps writing from where you left off by intelligently working out what should come next, hence Generative Artificial Intelligence.
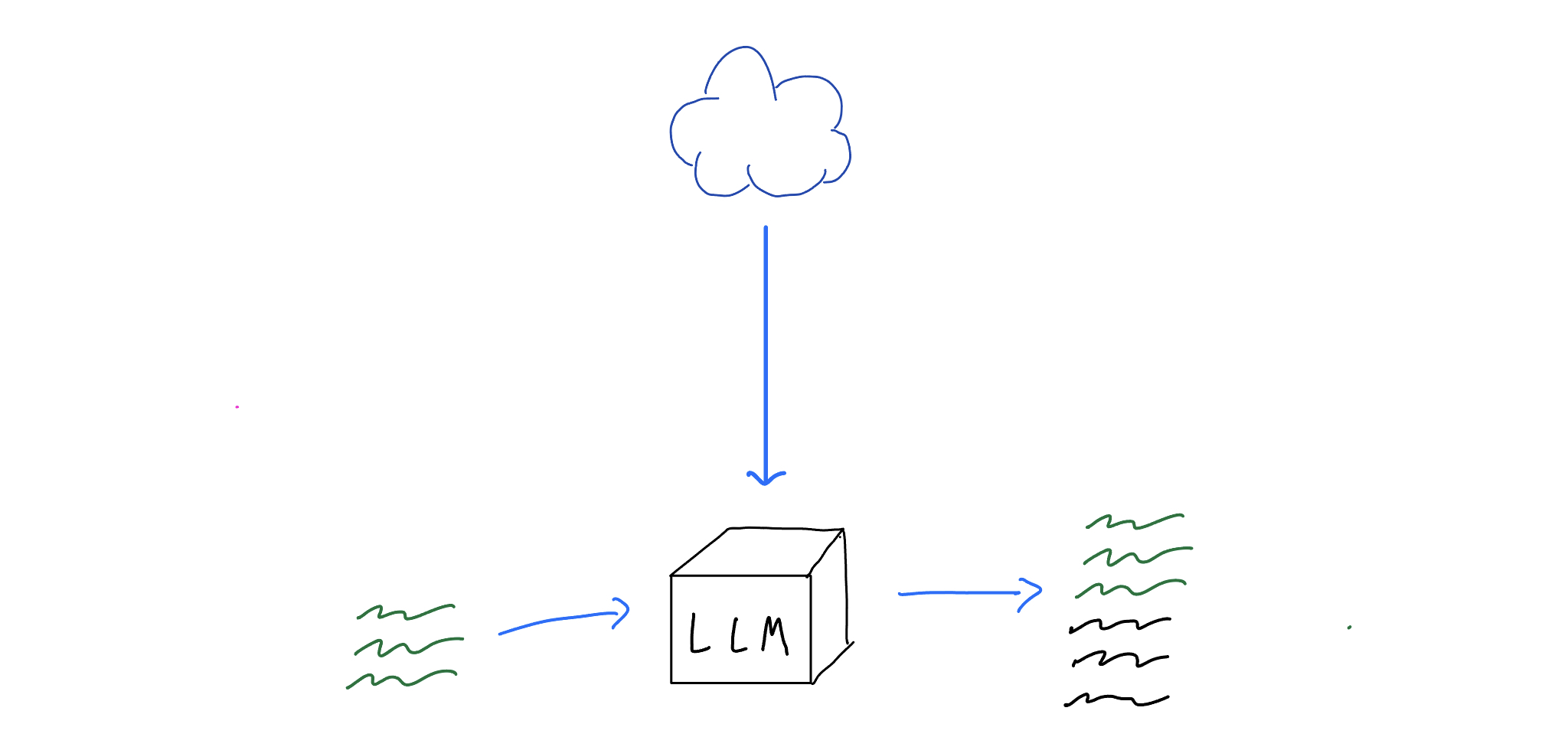
In the basic format, this gives text completion similar to playing the Story Game. That's not the easiest way of interaction, so most end-user LLMs today have been adjusted for chat instead of completion; you can converse with it in question-answer format.

Here's GenAI (LLM iteration) as experienced by most users today; a smart and knowledgeable system you can converse with in plain English[2].
From whence comes the knowledge?#
LLMs have two sources of information:
- Pre-training: Everything that was included in the training data when the LLM was first created
- Always known by the LLM in all interactions
- Can contain a LOT of data, includes pretty much all common knowledge and more
- Unable to be updated once the LLM is trained
- In-context: Anything that's included in the prompt when the LLM is used
- Only known within the current interaction
- Limited amount of data
- New and different info can be added whenever desired
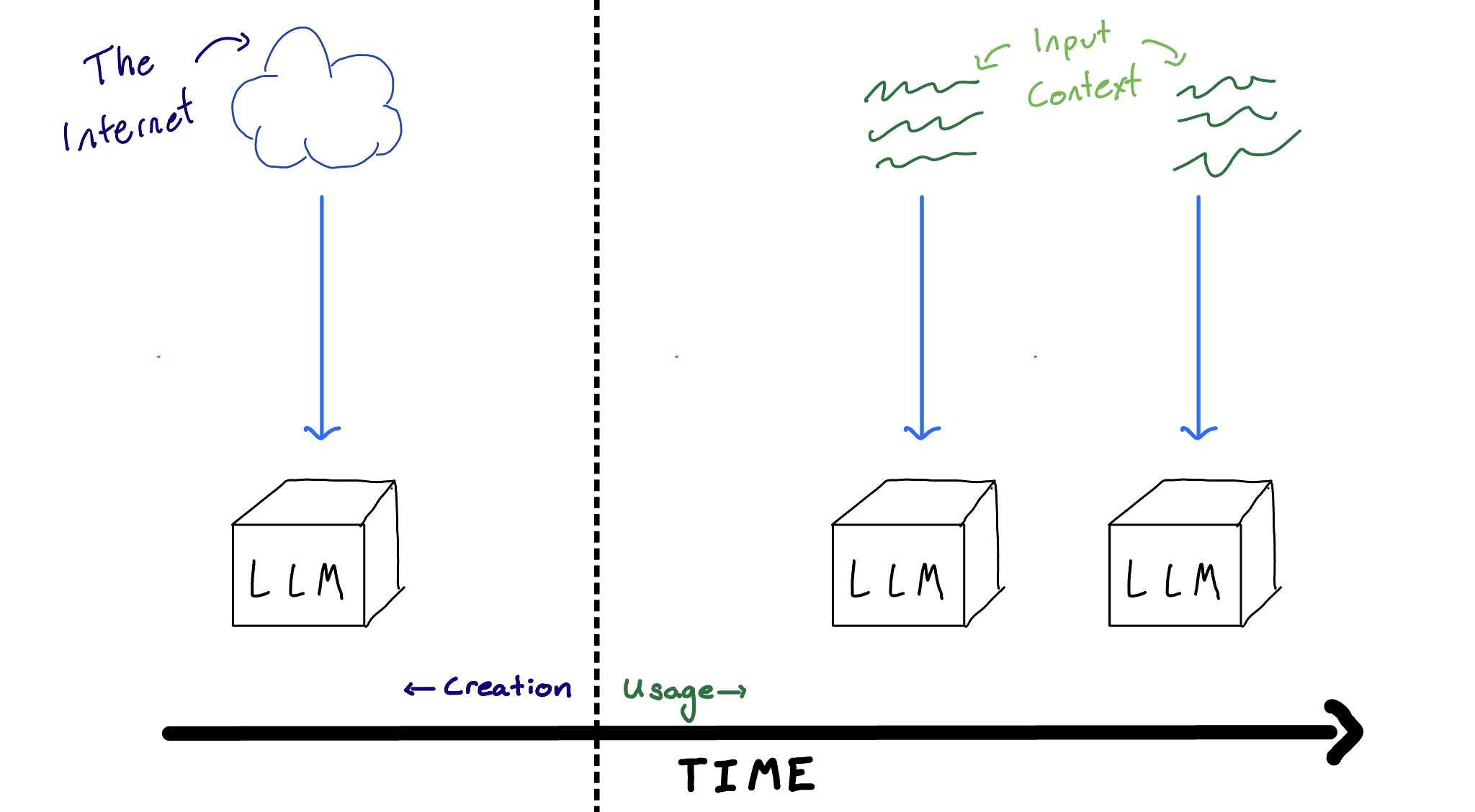
Pre-training data is a wonderful thing, with a truly impressive amount of knowledge squanched into the LLM. It's the best choice for scope, rememberance, and understanding. Unfortunately, it's a one-time-only type of deal for each LLM: pre-training is expensive and time consuming.
This is a problem, because the diagram above is a lie.
In reality, only part of the internet is included in pre-training (for many reasons[3]). Hence a lot will be missing from an LLMs knowledge bank, and it will be silent or misinformed if it needs to talk on such subjects.
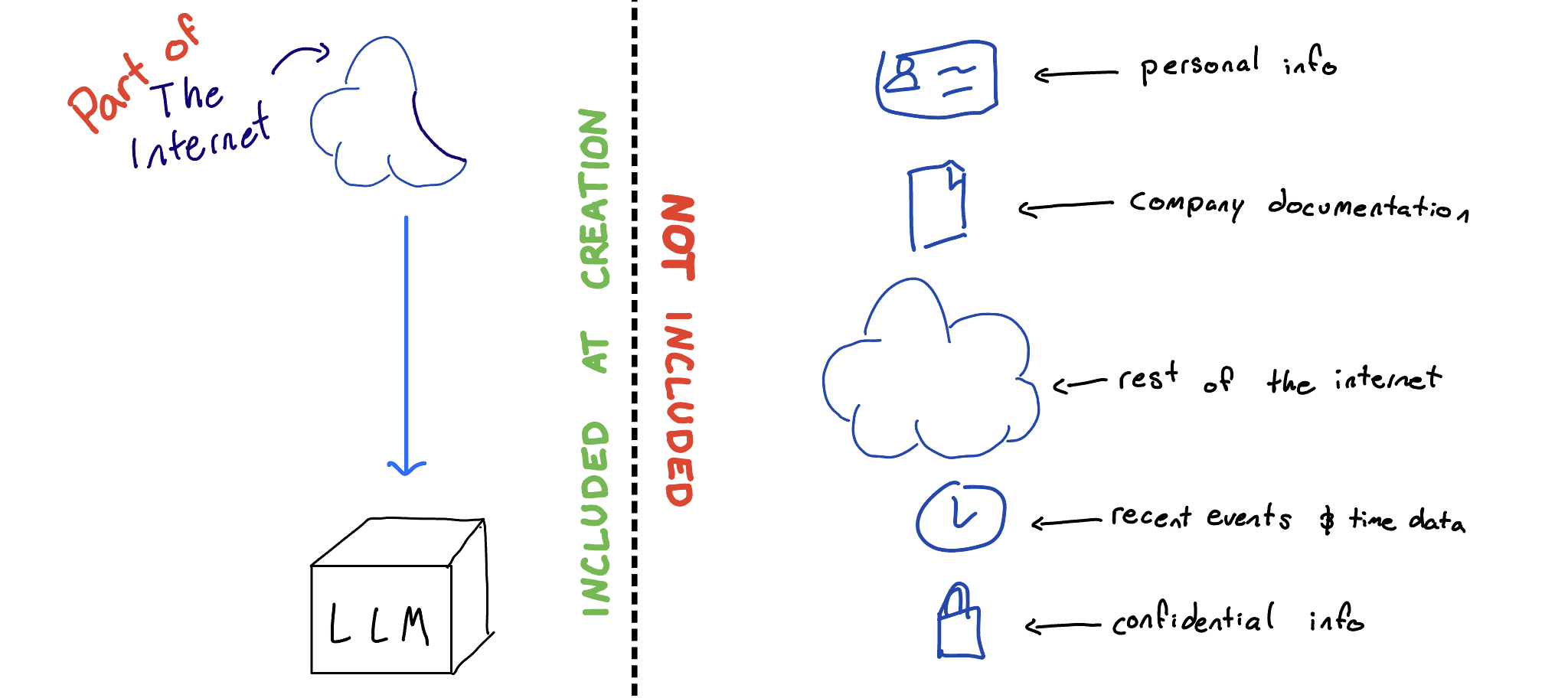
Any casual LLM user will run into these constraints.
Ask anything personalized, about current events, generally about something outside the model's knowledge? Many LLMs will [hallucinate]. Those more aware of their own limitations will ask you for more info.
Here we see one of the annoying problems that comes with LLM generation; but we also start to see hints of the solution.
The Problem:
There's some things that LLMs don't know. Sometimes this information is needed in order to get useful responses.
👁️🗨️ Tip
You can test this out with the Mistral Jon Snow Hugging Face Assistant. He gives examples on how to use OpenAI's chat-completion Python library.
Unfortunately, every example is wrong.
OpenAI deprecated the openai.Completion.create call in Nov 23, after [Mistral] finished retraining. Because his knowledge is out of date, the OpenAI calls given by Jon Snow will all return errors.
Augmenting the Context#
Babies babble. Have you ever been around one? Babies make lots of cooing, gurgling noises, which can be very cute but completely uninformative. This makes sense, since babies aren't particularly informed on how language works. Adults (generally) have that information, and thus can communicate significantly more effectively.
Even with adults, you easily see the difference between informed and uninformed conversation (cough generation cough). Just try asking directions from a tourist[1] instead of a local, and you'll feel the difference that information makes.
This is exactly the problem we've run into LLMs; they're very useful on familiar ground, but large chunks of the map are empty, ready for you to walk right off a cliff. Fortunately, ChatGPT was already telling us how to start solving this earlier:
We just need to tell it the information it's missing!
An intuitive understanding#
Any LLM user has probably followed this dance through before:
Once you've done this enough, you start to anticipate it:
Conversations with LLMs suddenly become a lot easier once you start telling it upfront the information it needs to know in order to contribute usefully[4].
In-Context Awareness#
Note
'Context' is essentially an LLM's short-term memory. This is limited; the Context Window is the amount of text or information the model can consider at one time when generating or understanding language.
This is the second type of information source [discussed above]; the LLM context. To fix the problem of missing information, you make the LLM actively aware of it in the current conversation.
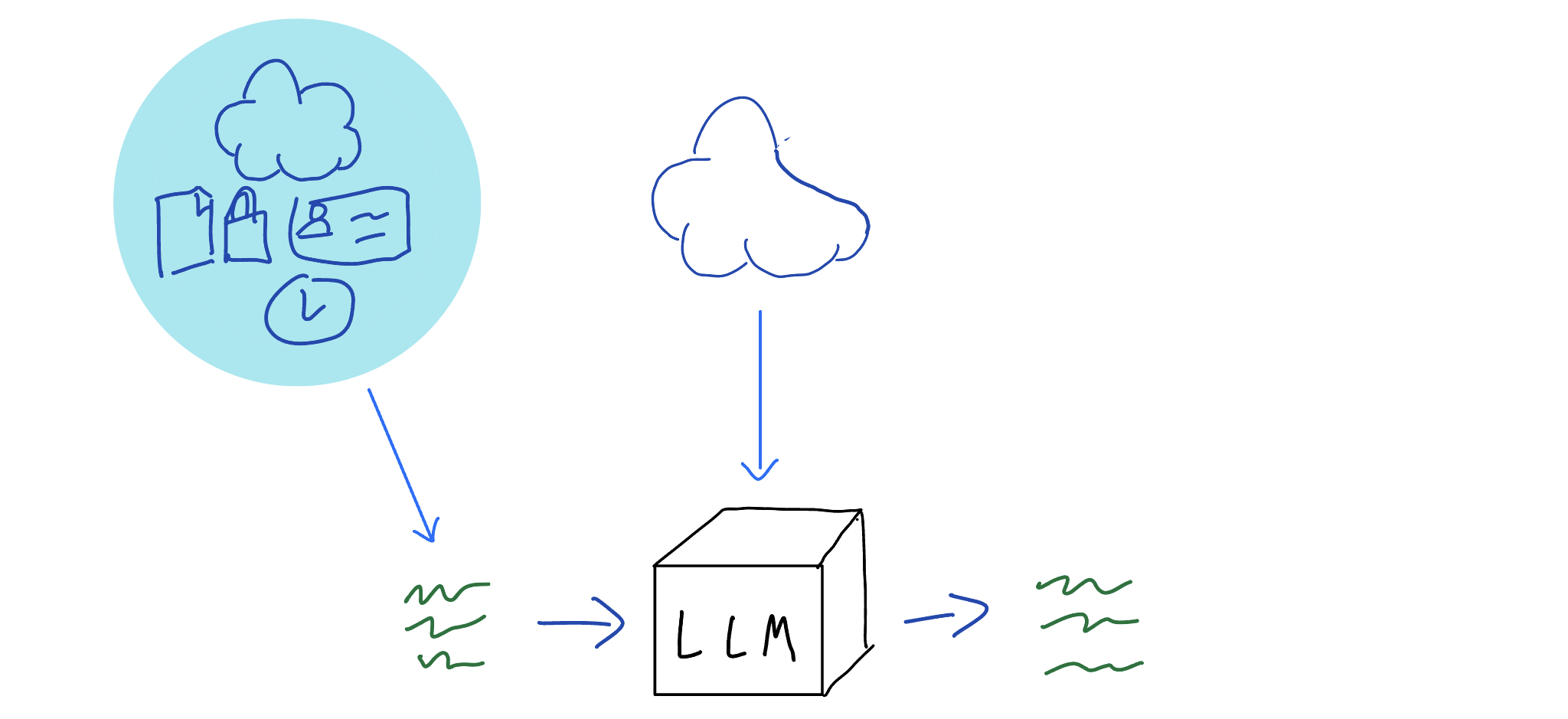
Doing this is easy, as you've seen earlier - just add the info in the input text given to the LLM. It does generally have to be textual[5], but other than that, you can just bung it in right before the user input or questions[6].
👁️🗨️ Tip
You can test this out with this Ygritte Hugging Face Assistant. Like Jon Snow, Ygritte gives examples on how to use OpenAI's chat-completion Python library.
However, the difference is in the system prompt. For Ygritte, I included a couple paragraphs from one of OpenAI's guides to text generation and one additional line saying "Use the documentation above to answer."
This change to the input information means that Ygritte will now correctly use client.chat.completions.create to access the OpenAI completion API. Augmenting the context with additional information has given us an Assistant that's actually useful to it's purpose[spoiler!].
A simple enough solution, telling the LLM what it needs to know ahead of time. All the same, it's quite a powerful little trick. ChatGPT seems to inject the current date [into the system prompt. This seems a clean way to resolve our issue.
The Problem:
There's some things that LLMs don't know. Sometimes this information is needed in order to get useful responses.
The Solution:
Add the needed information into the LLM context.
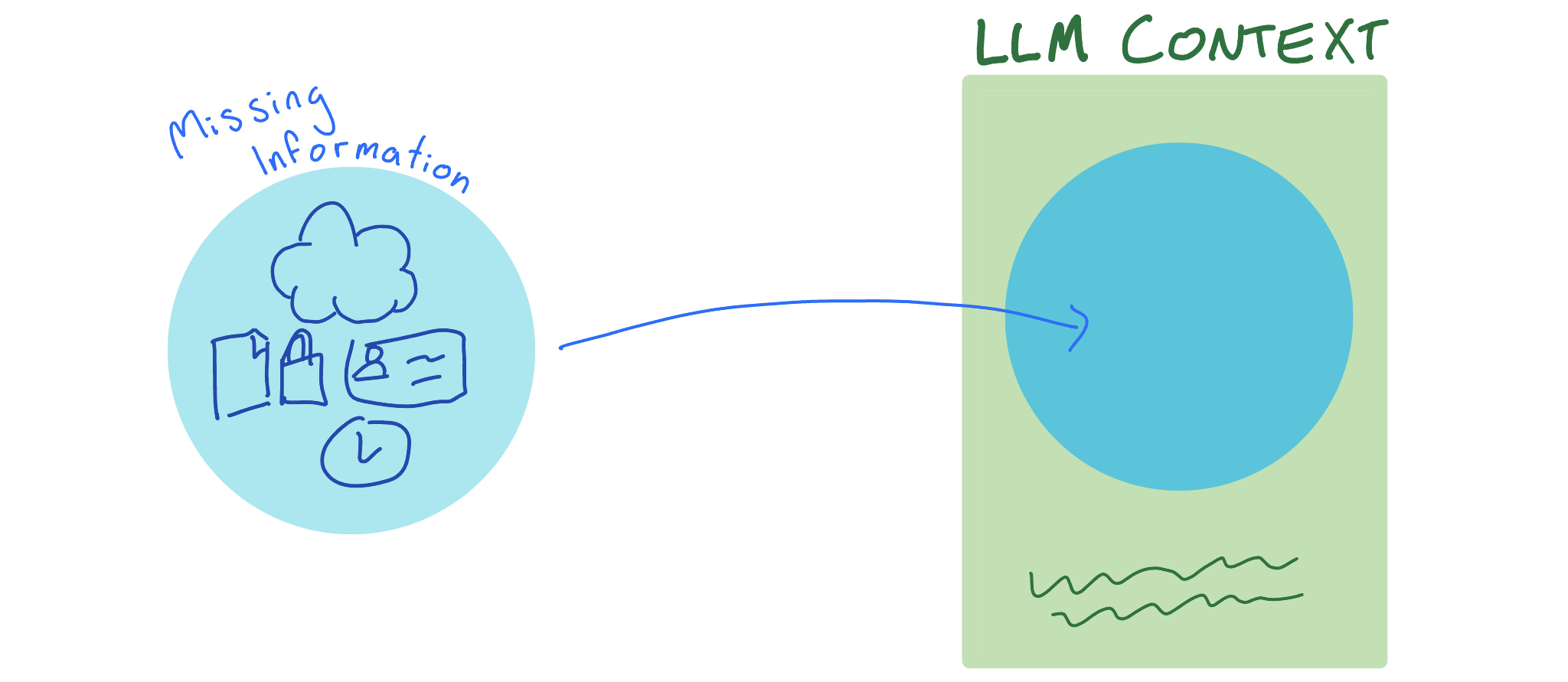
The inevitable issues#
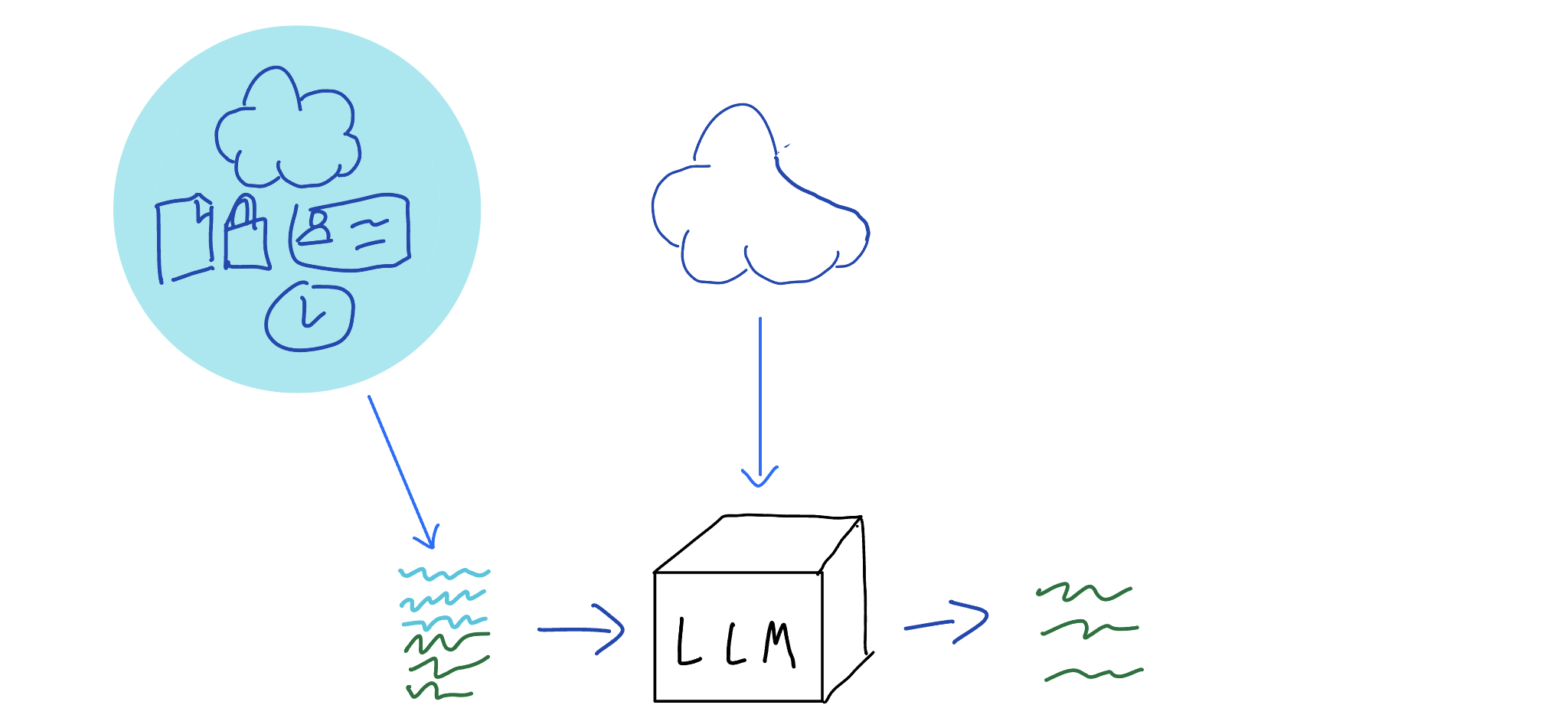
Nothing is ever that simple. The problem with this easy augmentation comes from two sources:
- There's a lot of missing info which may be needed
- Each LLM context window (short-term memory) is limited
This can be represesnted by correcting the earlier diagram to be somewhat closer to reality:
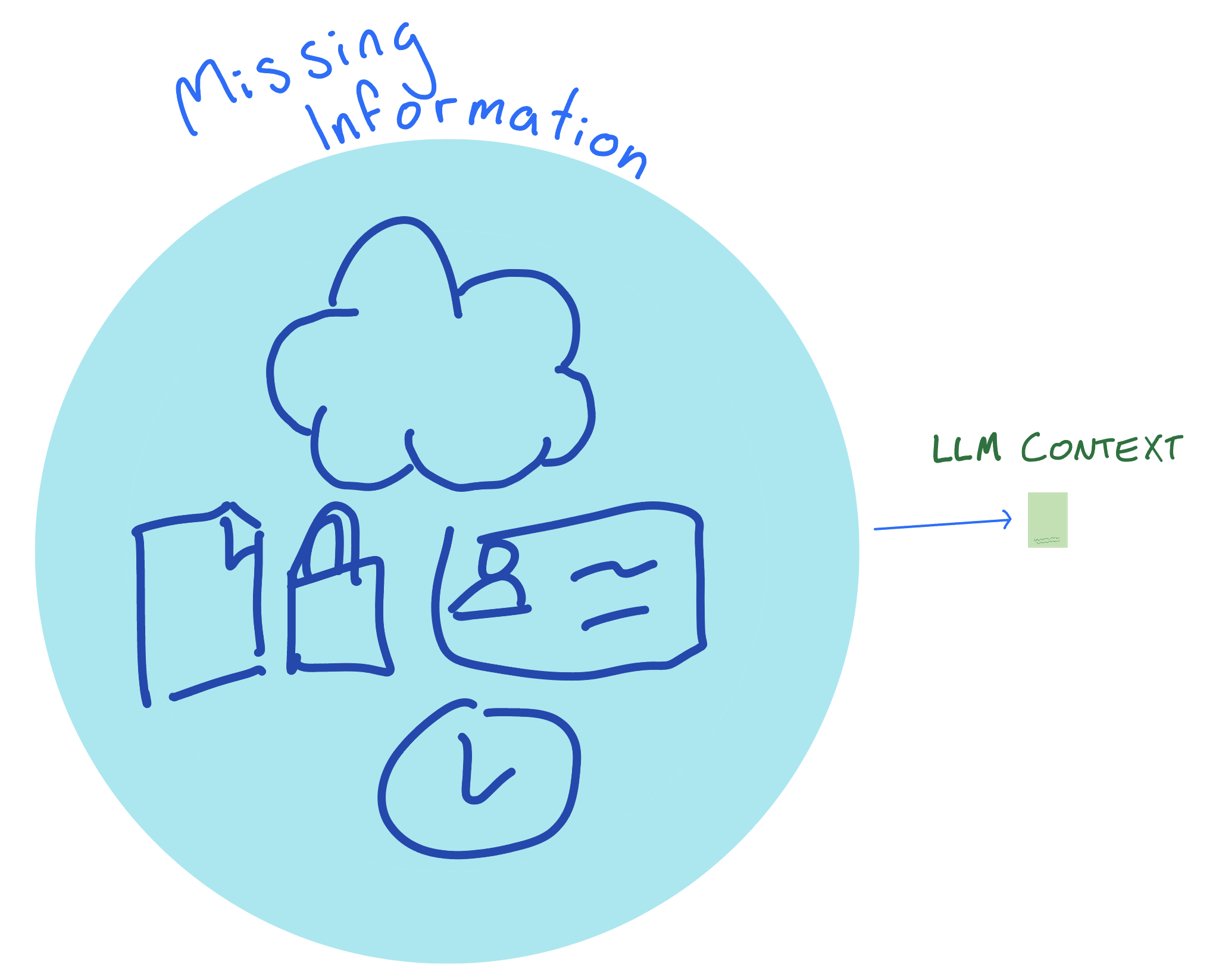
Clearly the missing information does not all fit into the LLM context. To an extent, your potentially-relevant information set might be limited from the start. In the ongoing example of the Hugging Face Assistants for OpenAI API usage, the dataset they need is the OpenAI documentation. Unfortunately, even that dataset is going to be too large for the ~50 page context window of Mistral once you consider all the how-to docs, API references, forum questions, release notes, etc.
We're saved by a third point:
- Only a small amount of the entire missing information will actually be relevant to any specific LLM interaction
This means we can reduce the information given to the LLM context with two steps.
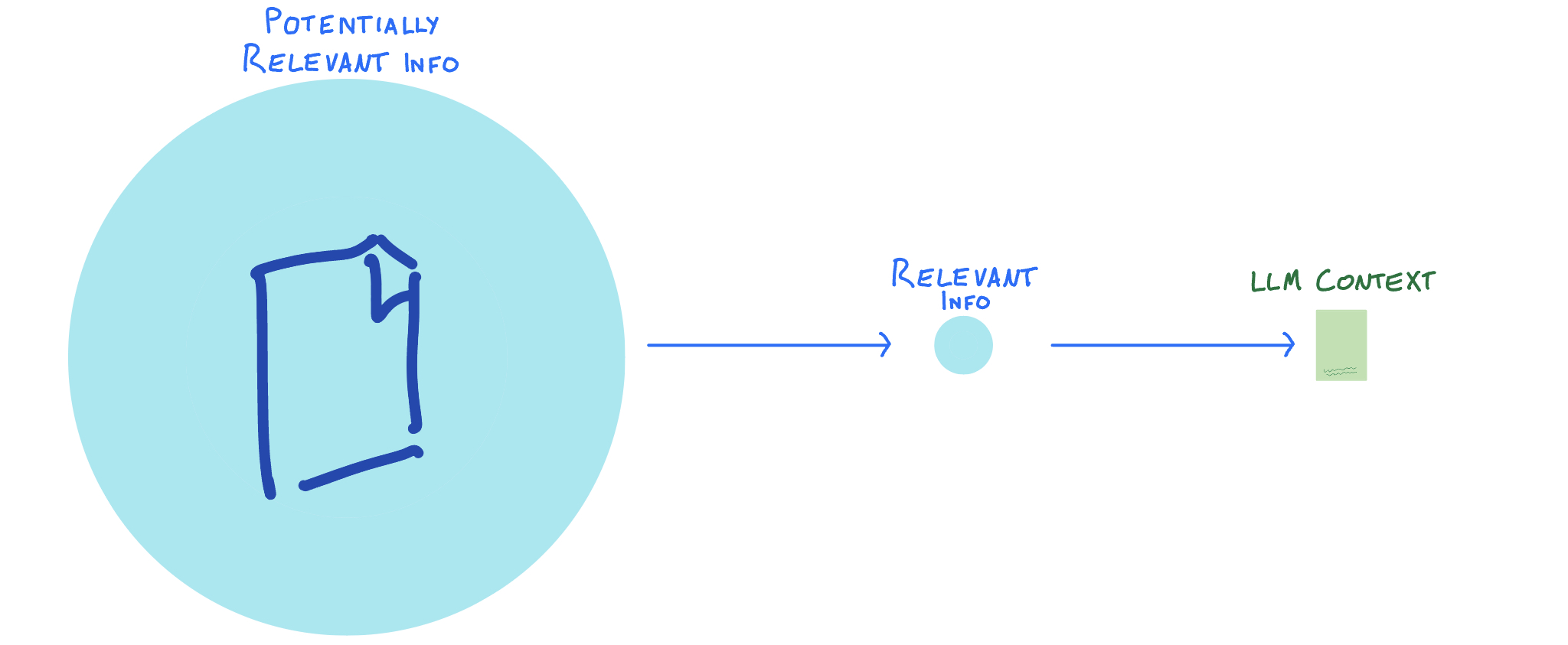
Both of these happen at different times, with different parameters.
It's now that we start thinking of how LLMs can be used in applications. The new AI world isn't just about people talking directly to the LLMs; it's about using them to support other programs, or adjusting them for specific purposes. We've seen this throughout in the Hugging Face Assistants; these are AI [agents] which are (nominally) meant for the specific purpose of helping people use the OpenAI offerings.
So narrowing down the potentially relevant info happens when an AI agent is first being created and is determined by what this specific agent needs to know in order to do its job. Finding the relevant info, compressed enough to be injested by the LLM context, happens during use and depends on what questions the user asks.
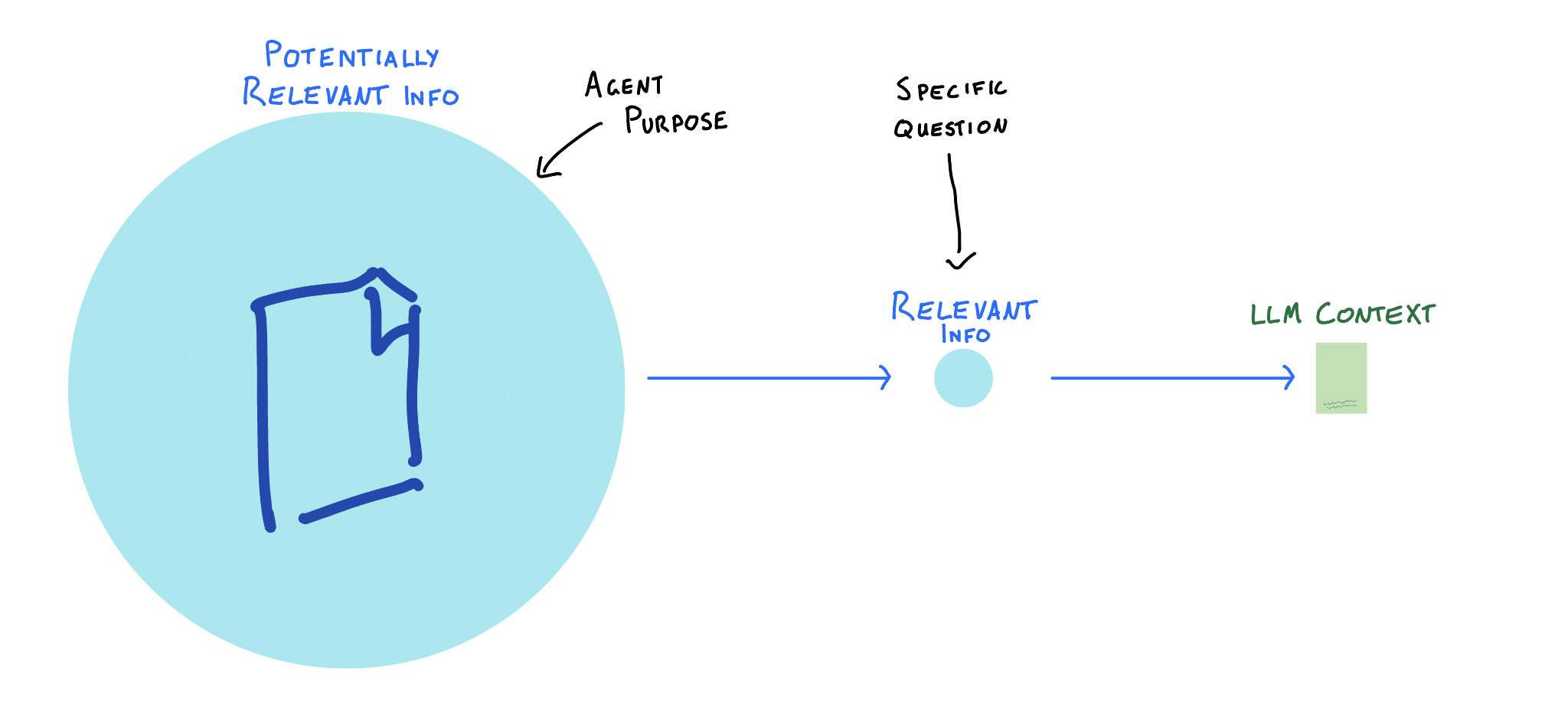
For an OpenAI assistant, this would look like:
- Purpose: Answer questions about how to use OpenAI's offerings clearly and well
- Potentially Relevant Info: All available OpenAI documentation, examples, forum posts, updates, etc.
- Question: "How do I use the chat API in python?"
- Actually Relevant Info: The Chat Completions documentation and the Chat API reference
The first step - working out what potentially relevant data is for your agent purpose - is usually fairly straightforward. Once you're there, the problem is how to extract the actually relevant information for every interaction.
The Problem:
Once a user asks a question, how do you find the useful data from a large dataset?
Retrieving Relevantly#
This one's pretty easy.
The Problem:
Once a user asks a question, how do you find the useful data from a large dataset?
The Solution:
Search.
Get the user input, and search the dataset for the most relevant material. Everything everywhere does this, including the very OpenAI documentation itself:
Here we finally see the full RAG pipeline:
- Get the user input
- Retrieve info from your dataset relevant to the user input
- Augment the LLM context with this info
- Generate an answer with this added knowledge
👁️🗨️ Tip
You can test this out with the Varys Hugging Face Assistant. Unlike the earlier assistants, he can answer a question about any OpenAI offering.
When Varys is asked a question, he first does a search on the openai.com domain to retrieve relevant information. This information then augments the LLM context in order to inform the answer generation.
Thanks to this implementation of the full RAG pipeline, Varys is actually useful for purpose!
This is very simple in theory, and can also be simple in practice. Or not. Search is a [massive industry], with many different implementation options.
Quick considerations#
There's many things to keep in mind when working out how to actually search your dataset. Off the top of my mind:
- Speed: will results return quick enough to avoid users getting annoyed?
- Input usefulness: does the input already contain all the keywords I need? Are there any assumptions?
- Question complexity: how much variety of information do I need?
- Result size: is this small enough to fit into my context[7]?
- Further reduction: if I get too many results, how do I cut it down further?
Easy retrieval implementations#
There's two basic types of search to start the RAG conversation: string search and embedding search.
You don't need to be a programmer to know string search, you just need to use google. This is the familiar concept of taking the words in the input and finding the sections of your dataset that have the same words. A broader category than just [exact substring matching], this can include [fuzzy matching], [approximate string matching], and [semantic search]. All code languages will have a function for at least the first and likely libraries for the rest, and computer science graduate will have implemented an entire algorithm from scratch.
[Embedding search] is another recent[8] gift from the AI overlords. Words or phrases are converted into numerical vectors ([embeddings]) in multi-dimensional space, allowing for semantic relationships to be captured. These embeddings are then used to compare and match similar words or phrases in a more meaningful way than traditional string matching techniques. In short, they're a more complex form of semantic search with a much bigger brain.
I won't get further into the details of embeddings; that's another article for another day. Hopefully you're convinced enough that search is something that has been conquered before (many times before) and can be conquered again.
The Problem:
Nothing! Nada! Everything is golden!
A Basic Implementation#
Let's create an itsy baby RAG system for a News Broadcaster AI agent. This will use the dataset of current events to give informed answers to user questions.
Retrieval#
This will use the newsapi as dataset and retrieval in one. When the user asks a question, we search for relevant current events using this API.
def retrieve_relevant_news(input_text):
keywords = get_keywords(input_text)
newsapi_url = ('https://newsapi.org/v2/everything?q='
+ '&q='.join(keywords)
+ '&from=2024-03-10&sortBy=relevancy&searchIn=title,description'
+ '&apiKey=' + newsapi_apikey)
response = requests.get(newsapi_url).json()['articles']
useful_results = [item['title']+"\n"+item['description'] for item in response if item['source']['id']][:10]
return '\n'.join(useful_results)Note that the results are being trimmed for only ones that actually include data, and limited to only 10.
This is a search mechanism that relies pretty much entirely on an external service, although there may be some cleverness in the get_keywords() function[9]. However, it does work:

Augmented#
Both the external retrieved information and the user question should be put into the context. Most LLMs use a message array for this.
def augment_context(retrieved_data, input_text):
augmented_context = [
{
"role": "system",
"content": "You are a news broadcaster. Always let the user know about the details in the following news:\n" + retrieved_data
},
{
"role": "user", "content": input_text
},
]
return augmented_contextMassaging the prompt associated with the retrieved data is an easy way to start getting better answers.
Generation#
With your message array prepped and augmented, getting an answer is a simple matter of a call to your LLM of choice. Here I'm using the OpenAI chat API - the same one that all the Hugging Face Assistants are there to help with.
def generate_answer(augmented_context):
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=augmented_context
)
return response.choices[0].message.contentPutting it together#
Run each piece in sequence:
def run_rag(input_text):
print("Question asked:", input_text)
retrieved_data = retrieve_relevant_news(input_text)
print("\nRETRIEVED information:\n", retrieved_data)
augmented_context = augment_context(retrieved_data, input_text)
print("\nAUGMENTED context with the retrieved information")
answer = generate_answer(augmented_context)
print("\nGENERATED answer:\n", answer)
return answerTada! One complete RAG setup.
I've added a little more juice to make it command line runnable, and you can find it as a gist. Here's a demo of it in action, but please do copy it over and run it yourself as well!
Keeping Current#
Now that the concept of RAG is clearly understood, let's take a step back and place it in the world of today.
Colloquial definitions#
RAG is one of those broadly-used terms that seems as though it should have a well-spec'd definition, but is really just vibes.
Here's some general principles to work from:
- RAG is generally a LLM-specific term, despite "generation" being pretty broad. For instance, I've yet to see any 'RAG image creation' projects.
- Retrieval generally means 'search of a specific known subset of documents'.
- Linked to the above, it's questionable whether tool usage is considered RAG. More specifically, web search retrieval generally isn't, from what I've seen, called RAG.
- The above is all flexible and very dependent on the hype train of the day.
Breaking the Basics#
RAG is the latest fad - how can you be special?
Popular things are populat because they're great, but it then becomes difficult to do something great that nobody else has thought of. However, there's a couple of different spaces which allow for a distinctive edge.
First, dataset. If you can bring a specialized, useful dataset that other people don't have access to (or don't know very well), you can build something novel. Web search, useful as it is, has been done before.
Second, retrieval system. This is where a lot of the heavy lifting happens. The search element is the entire point of a RAG system, but as anyone who uses Google knows, it can be difficult to actually find the right results. Hrishi's written a good series on ways to improve.
Finally, generation. This is the realm of prompts, priming, possibly even fine-tuning. Massage the output to be something people like reading!